
When I was younger, I would occasionally hear about higher math classes that one was able to take. To me, then a naïve high schooler, AP Calculus represented an attainable pinnacle of mathematical knowledge beyond which lie a plethora of weird maths to explore. I had heard of multivariable calculus, which sounded like more of the same with more letters, differential equations, which was just calculus with more tricky problems, and so on and so forth.
However one, linear algebra, seemed like a mystery. It’s name evoked, to me, the kinds of problems done in middle school where I was painstakingly asked to grind through systems of three equations to find 
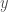

Spoiler alert: It wasn’t, and, while related, linear algebra really isn’t about that stuff. It’s actually about a lot of other, cooler stuff, including really cool stuff like quantum mechanics.
Note: This is just a primer on linear algebra. I introduce the axioms, and then paint over the subject with a broad brush that isn’t meant to be comprehensive. Quantum mechanics is inseparable from linear algebra, so I try to get to the meat of linear algebra while not glossing over too much. At the same time, this obviously shouldn’t be taken as a substitute for a more rigorous treatment of linear algebra.
Part 1: The Abstract
All throughout grade school, I was decent at math, but I was lacking one key piece of mathematical maturity: I relied on intuition to do math, and struggled when that failed. When looking at a function, I would imagine the graph. When doing trigonometry, I would imagine triangles. I did calculus by imagining the summing up of little pieces rather than by working through the more rigorous sea of Riemann sums and so on.
While this isn’t really all that bad for most everyday purposes, it certainly becomes a problem when trying to do upper level math. It took a long while for me to realize that math isn’t so much about describing physical things (which is the domain of physics), but more about asking the question what if? about increasingly abstract concepts and working out what would happen. It’s about assuming certain statements, called axioms, and deriving results, called theorems in order to understand what an object that followed said axioms would behave like.
For the reader who is new to such thinking, I caution you: use your intuition, but don’t get caught up in what “all this stuff is, really?” A lot of it is going to sound vague, but that sort of answers the question of what this stuff is about, which is, as it turns out, a whole lot of stuff.
For this introduction to linear algebra, I will use some mathematical notation in order to ease in the more compact notation for what I’m saying. However, I will be sure to explain what I’m saying in normal well-adjusted human language in close proximity when I do so. I also won’t bother proving every single statement, but will be sure to prove some of the more important ones.
This introduction is about the theory of vector spaces and linear transformations, rather than the computational, matrix-math aspect of linear algebra. Admittedly, that’s leaving a lot out, but hopefully this is a helpful overview of a summary course on the subject.
Part 2: A Theory of Vector Spaces
Definition: A field is a set 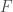
: The rational numbers, numbers which can be expressed as a fraction of integers
: The real numbers, numbers which each represent a point on a number line
: The complex numbers, a set of numbers big enough so that every polynomial equation as a solution in
such that $i^2=-1$. Don’t think too hard about how this is possible, this is what I mean by asking what if?)
- Finite fields like
,
,
, etc. These are less intuitively but still technically fields. While they are fun and interesting in their own right, I will ignore them since they won’t be all that interesting for the end goal here, which is understanding how linear algebra is related to quantum mechanics.
I will commonly refer to objects in a field as numbers or scalars.
Definition: A vector space 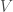
(vector addition). These symbols just mean that there is an operation called
which takes two vectors which are in the vector space
(scalar multiplication). This is an operation that takes in a number from the field
symbol and just write the scalar next to the vector. For example,
In addition, in order for
Vector Addition Axioms:
. For any two vectors in
. For any three vectors in
s.t. (“such that”)
. There is a special object, which I’m calling
for now such that, when I add it to another object, the result is always that other object. From now on, I will call this vector
. I will justify why I can do so in a bit. This is saying that there is a zero vector, also called an additive identity.
s.t.
. This is the statement that, for every vector, there is some other vector which, when added to the first vector, gives
. I will justify this later as well. This is the notion of additive inverses and basically tells me that I am allowed to do subtraction (which is just glorified addition involving inverses).
Scalar Multiplication Axioms:
. The
on the left is the
. If I multiply a vector
and then multiply the result by another number
, I will get the same thing as if I multiplied those numbers together to get
and then multiplied the result by the vector
Distributive Axioms:
. Scalar multiplication distributes over vector addition.
. Scalar multiplication distributes over scalar addition.
These two axioms are the familiar distributive property.
All of these axioms may seem like a lot to keep track of, but the key thing to take away from this is how familiar they are. You should really think of vector spaces as collections of objects which can be added together and scaled up or down by numbers. If this sounds like it would apply to a lot of things, that’s because it does.
Some Loose Ends:
In this section, I want to justify a few of the claims I made before. I first said that I would just call the additive identity
Theorem. The additive identity is unique.
Proof. Suppose there are two additive identities, 




In addition, I never showed that each vector has a unique additive inverse.
Theorem. Each vector has a unique additive inverse.
Proof. Let 




Another important theorem which is extremely important to understand but which isn’t an axiom because it can be proven from the other theorems:
Theorem. 
Proof. For any 

Finally, we should establish some notion of vector spaces being encapsulated inside of other vector spaces.
Definition. A set is a vector subspace of another vector space if (1) it is a subset of that vector space, and (2) it is a vector space with the same operations and field as that other vector space.
Linear Independence
So far, we have defined what a vector space is, and we have proven two fairly simple but important theorems about vector spaces. Implicit here is that I have really proven them about all vector spaces. If I ever have a system that seems pretty complicated and unwieldy, if I can show that it is a vector space, life becomes a lot simpler.
What other conclusions can we draw about these increasingly fascinating objects?
Definition. For a set of vectors 

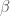
Definition. A set of vectors


If 
At first, this seems like some random definition I made up for no reason. However, we can prove a theorem which demonstrates why linear (in)dependence is interesting.
Theorem. If a set of vectors
Proof. If 


and then divide:

Notice that the key here is that 
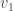
The implication here is that, if a set of vectors is linearly independent, you cannot write any of them in terms of each other. There is also another useful theorem about linear independence.
Theorem. Any set containing the zero vector is linearly dependent.
Proof. Take the set 

Note that the first coefficient is nonzero, so there is some nontrivial linear combination of vectors in
Spanning and Bases
Definition. A set of vectors
Definition. A basis for a vector space
Bases are super duper important in linear algebra because of one really important theorem.
Theorem. If
Proof. First, every vector in 

and

where 

and then rearrange:

Since 



These coefficients are called the components of a vector in a certain basis.
Another fact about bases that I won’t prove is that every basis for a so-called “finite-dimensional” vector space has the same number of vectors in it. The dimension of a vector space is just the number of vectors in its basis, and a finite-dimensional vector space just means that a basis for the vector space doesn’t have an infinite number of vectors in it (infinite-dimensional vector spaces are also very important in quantum mechanics and other things, like Fourier analysis).
Linear Transformations
So far, I’ve only talked about vector spaces and the vectors in them. However, I haven’t really talked about functions from one vector space to another. They are quite important, however, so let’s talk about them.
Definition. A linear transformation 
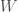


In other words, linear transformations “distribute” over vectors, in a sense. Really, though, this is what it truly means to be linear, hence the name “linear algebra.” As boring-sounding of a term it is, it certainly is accurate.
Definition. A linear operator is a linear transformation from a vector space to itself.
Definition. A linear transformation is one-to-one (or injective) if 



Definition. A linear transformation from a vector space 
Definition. A function (not necessarily linear) which is both one-to-one and onto is called a bijection. A linear transformation which is a bijection is called an isomorphism.
An isomorphism is basically the notion of a transformation which connects every single vector in one vector space to every single vector in another vector space, with no overlap.
Some other very important facts about linear transformations that I won’t prove:
- Linear transformations can be composed, i.e., turned into another linear transformation which is when one linear transformation is performed after another. This is equivalent to matrix multiplication and, while not commutative, composition is associative.
- A linear transformation which can be undone by another linear transformation is called invertible, and the latter linear transformation is called the inverse of the former.
- Two finite-dimensional vector spaces which have some isomorphism between them are called isomorphic and must have the same dimension.
- The vector space
is just an ordered tuple (list) of
scalars. It can be shown that a finite dimensional vector space over
- To get meta for a second, linear transformations from one vector space to another are, themselves, a vector space. You can add linear transformations together, scale them, define a zero linear transformation, etc. You can then define linear transformations over this vector space, then take the set of all of those linear transformations, define linear transformations for those, and so on and so forth.
Eigenstuffs
In general, linear operators, linear transformations from a vector space to itself, do really weird things to vectors. They can send them in places which are not intuitive. However, there are certain vectors which are mostly unaffected by a given linear transformation. Some vectors only get scaled up or down by a certain linear transformation. These vectors, as it turns out, hold the key to quantum mechanics.
Be warned: every word in this section starts with eigen-. It’s really important!
Definition. For a given linear transformation, an eigenvector

where 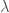
In order to find the eigenvalues of a linear transformation 

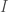
For many linear transformations, you can make a basis out of eigenvectors. Such a basis is called an eigenbasis. Note that, while the sum of two eigenvectors isn’t always an eigenvector, the following theorem is true.
Theorem. A linear combination of two eigenvectors corresponding to the same eigenvalue is also an eigenvector with that same eigenvalue:
Proof. Let 



Note that this makes eigenvectors of the same eigenvalue a vector space in their own right. They are a vector subspace of the original vector space. For an eigenvalue
Not all linear transformations have eigenvectors. For example, rotations in 2D by angles that aren’t multiples of 180 degrees (the vector space is 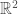
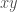
Inner Products
For everything before this section, we have discussed general vector spaces over arbitrary fields. I have never had to assume what the field was in order to prove any theorems. However, this next section works only when the field is either the real numbers,
Definition. For a vector space 


- Linearity in the Second Argument:
.
- Conjugate Symmetry:
. The star represents a complex conjugate. For a real number, this doesn’t do anything (which means that real inner products are symmetric, i.e., you can feed in two vectors in either order and get the same number. For a complex number
, the complex conjugate is
.
- Positive Definiteness:
, and
. This is saying that the inner product of every vector with itself is always greater than equal to zero (and also real). In addition, if the inner product of a vector with itself is
I will try to motivate why this definition, while at first abstract, is actually useful. Generally, vectors are introduced as arrows in space with direction and magnitude. However, I’ve deliberately avoided doing that because I didn’t want us to be overdependent on this picture in our heads of arrows floating in space, which sort of takes away from finer points of nuance in actually reasoning from the vector space axioms.
Indeed, if we look closely, we now have a mathematically rigorous definition of what we really mean by direction and magnitude. For the magnitude, or length, of the vector, we notice that all vectors have some non-negative length: no vector can have a length of 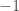


We may also address direction, which, if you think about it, really is all about telling the angles by which vectors are separated. It turns out that we can define the angle 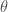


Definition. An inner product space is a vector space together with a specific inner product.
Note that you can always define an inner product, and there are actually, in all cases, an infinite number of inner products you can define. For example, a very common inner product is the dot product over real vector spaces, which is just when you expand two vectors in terms of their components in a basis, multiply their corresponding components together, and summing the resulting numbers. But you could always define an inner product where you do this same process, and then multiply by 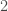
Definition. A basis composed of vectors that are all normalized and all orthogonal to each other is called an orthonormal basis.
Orthonormal bases have an extremely useful property that means physicists pretty much always pick them. In quantum mechanics, they are so ubiquitous that, when someone talks about a “basis,” they are always talking about an orthonormal basis. What is that property?
Theorem. Let 


Proof. We start with 
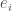

Since the inner product is linear over the second component, this implies that

Because 

so that
This gives us a very, very, very convenient way of getting the expansion coefficients of a vector in terms of a basis. Before, we said it was possible, but we never actually talked about how to figure out how to expand an arbitrary vector in terms of a given basis. If the basis is orthonormal with respect to some inner product, we have an easy way to do this. This is how the standard dot product works, since we almost always pick an orthonormal basis for this convenient feature.
We can ask if any vector space has an orthonormal basis. I never actually proved that that’s true. In fact, all vector spaces have an orthonormal basis. We can always construct an orthonormal basis from any basis by doing the Gram-Schmidt process.
Another important fact is that, if I take some orthonormal basis and define my inner product as the sum of the multiplied components of two vectors in that basis, it doesn’t matter which orthonormal basis I pick. I will always get the same answer.
Finally, we should note here the very important fact that eigenspaces corresponding to different eigenvalues are orthogonal to each other. All vectors in one eigenspace are orthogonal to all vectors in a different eigenspace.
Other Linear Transformation Definitions and Theorems
For this section, we’re going to assume some inner product.
Definition. Define the adjoint of a linear operator

where 
Definition. Call a linear operator

In other words, 
Theorem. The eigenvalues of a Hermitian operator are all real.
Proof. Let 

but also that

so that

Since 

which is only true if
In fact, not only is it the case that all the eigenvalues are real, it is also the case that you can make an orthonormal basis out of eigenvectors of any Hermitian operator, no matter what it is. This statement is called the spectral theorem.
Definition. A linear operator 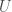

Basically, the way you should think about unitary transformations is that they are transformations which can’t change the length of any vector or the angle between vectors. While I won’t prove this particular statement, a unitary transformation will turn an orthonormal basis into another orthonormal basis. Unitary transformations also have their own special theorem about their eigenvalues.
Theorem. All eigenvalues of a unitary operator lie on the unit circle in the complex plane, i.e., if 
Proof. Consider

Then, since

as desired. ■
In addition, an equivalent and often-used definition is that a unitary operator is an operator whose inverse is the adjoint, i.e. 
Definition. A projection is a linear operator 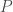

We have a theorem about the eigenvectors of a projection, also:
Theorem. The eigenvalues of a projection can only be
Proof. Let 

and, on the other hand, that

by idempotence, so that

or, rearranged,

Since 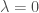

You can also always find an eigenbasis for a projection operator. There is a notion of “projection onto a subspace.” A projection can be thought of as taking all the components of a vector “parallel to” a given subspace, and throwing away the rest. It’s a tad bit like how your shadow is like the shape of your figure, but only the parts parallel to the ground.
Another concept that we should be somewhat comfortable with, if only conceptually, is the idea of exponentiating linear operators. For example, I can write down 
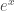

Then, we have a convenient way to define the exponential of a linear operator

where 
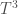
Part 3: The Quantum Mechanics—The Postulates
What I’m going to try to do here is lay out the straight math underlying quantum mechanics. I’m going to leave it extremely barebones, which means even leaving out such things as Schrödinger’s cat or the stock first-year-quantum-class exercise of integrating over a wavefunction to get the probabilities. I’ll even leave out here most of the physical interpretation, instead jumping into the skinniest of descriptions as to how the math works.
Postulate 1. In quantum mechanics, the state of a system corresponds to a vector in a vector space called a Hilbert space, which is an inner product space. These “state vectors” are called kets. The Hilbert space is always a vector space over the field of complex numbers
Really, the only vectors in this Hilbert space that are physical are the ones with length 
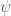
Postulate 2. Every observable variable (observable) has a corresponding Hermitian operator on the Hilbert space, and every Hermitian operator corresponds to an observable.
In quantum mechanics, operators are written as letters with hats on them, i.e., 
Postulate 3. If you try to measure a variable corresponding to a Hermitian opreator, your outcome will be one of the eigenvalues of the Hermitian operator.
Note that the outcome of the measurement is always going to be a real number, since Hermitian operators have real eigenvalues. Operators that aren’t Hermitian in quantum mechanics still have a role to play, but do not correspond to physical observables.
Postulate 4. If you have the state 
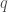


Basically, the probability of measuring a given eigenvalue is the squared length of the projection of the state vector onto the eigenspace corresponding to that eigenvalue.
Postulate 5. After measuring the observable 
Basically, once you measure the eigenvalue, the only part of the state that remains is the projection along the eigenspace corresponding to the measured eigenvalue
Postulate 6. The evolution of a ket in time, assuming it hasn’t been measured, is

where
Another way to put this is that, in order to time-evolve a ket from time 


In contrast, collapse after measurement is non-unitary time-evolution, since the time-evolution of those vectors is not as simple as applying a unitary operation. Note that, since unitary operations are always invertible, you can, in principle, undo the changes that happen to a system as long as you do not measure anything. Interestingly, for this reason, quantum computers can’t practically do things like AND gates and OR gates because such gates are not invertible (if I told you that A AND B is true, you still would not be able to tell me what A and B were, individually).
Some other notes. I have introduced the Hilbert space of kets as state vectors. I can also introduce this notion of a bra, which is defined to be the operation of taking the inner product of a given ket with something. For example, the 

where 


where the right hand side is called a bracket. Thus, you see one of the cheesiest puns in all of physics. A “bra” written beside a “ket” gives a “bracket,” which is always just some complex number. This bra-ket notation, also called Dirac notation (who must have been an excellent punster in life, if he was even the person to come up with these words), simplifies the notation of quantum mechanics drastically. For example, to enforce that physical kets are normalizable, I may simply write

The average value of the operator 

where the right hand side means that I act

where I leave it to you to see why this is an operator. This also happens to be, out of coincidence, the projection operator onto the subspace corresponding to a positive measurement of the state being in state
Part 4: The Two-State System
In order to show these postulates in practice, let’s consider the two-state system. This is a simple example of a quantum system occupying a Hilbert space that is two dimensional.
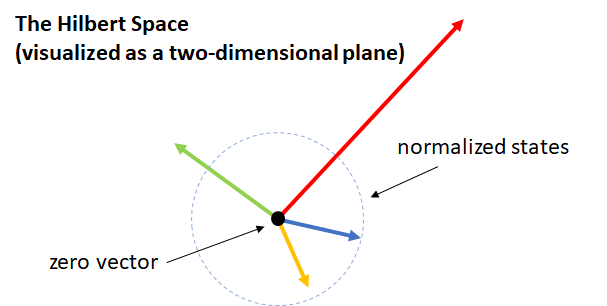
While the representation of the Hilbert space above as a two-dimensional plane is a pretty good visualization, it masks the fact that this is a complex vector space, whereas the plane is really a better representation of a real vector space. To make this more concrete, let’s call the normalized ket pointing to the right 

and one that points down and to the right is

However, it’s difficult to visualize, for example, the following state:

In fact, in general, we could have states that look like this:

where 



Suppose I wanted to measure whether the state is in state 





after which the state would collapse to state
In a way, this state is an “equal superposition between
The answer is that the relative phase doesn’t affect the probability of measuring this particular observable. However, we can instead consider the observable corresponding to whether or not the state is in state 





after which the state would collapse to state 
We see that the probability of measuring the state $latex \lvert\psi_\varphi\rangle$ in state 



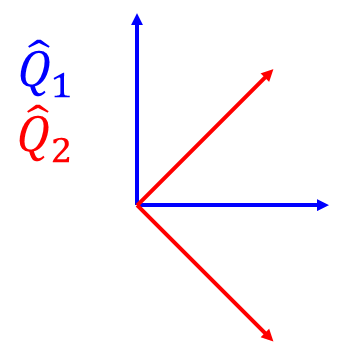
The basic gist of what would happen here is this: if I measure 
While a bit more nuanced, in quantum mechanics, a similar thing goes on with position and momentum. If you measure the position over and over again, you will get the same answer each time. However, if you measure the momentum, the state will collapse to an eigenstate of the momentum operator, and, if you measured the position again, it wouldn’t be in the exact place anymore. In fact, if you measured the momentum perfectly, it turns out that you lose all position information. This underlies Heisenberg’s uncertainty principle between position and momentum, which says that the product of the uncertainties for position and momentum 

Now, this two-state system seems like a pretty abstract quantum system, but it’s actually not. Many systems are effectively two-state systems. This includes
- The polarization of light
- The spin of an electron
- The energy level of an electron in an atom if only two levels are realistically likely
The two-state system is really important in quantum information and computation, the underlying idea of which is that the weirdness of quantum mechanics can be used to solve certain problems which cannot be efficiently solved by classical computers. By efficiently, I mean it would be nice to solve certain problems before the heat death of the universe trillions of years from now, but for some problems we actually can’t do that with classical computers. That’s not a really high bar for efficiency, but some problems, like factoring semiprime numbers (which is relevant for a security protocol called RSA) are really that hard.
The fundamental unit of these quantum computers is the quantum bit, usually abbreviated to qubit. Each qubit is a two-state system. If you consider 



Part 5: Going Further
I have covered here a basic overview of linear algebra and introductory quantum mechanics. Of course, if you want to be able to do any of these subjects, go beyond this summary and explore these beautiful subjects. In this section, I’m going to discuss some topics which are cool extensions of linear algebra and quantum mechanics.
Linear Algebra
- Numerical linear algebra, which is the use of algorithms to do linear algebraic operations. Note that matrices are very important in computation because it turns out that, while, say, humans have a difficult time inverting matrices and stuff like that, computers are actually quite good at it. It’s also extensively used in subjects like machine learning.
- Abstract algebra, which is a generalization of linear algebra (hence the “linear” part is replaced by “abstract”). One key object in abstract algebra is that of groups (the study of which is called group theory), which are this generalized algebraic structure which basically underlie the mathematical study of symmetries. Other objects in abstract algebra are rings (ring theory), which are specific kinds of groups or, if you would like, generalized fields (for example, the integers
are not a field, but they are a ring), and modules, which are like vector spaces except, instead of being over a field, they only have to be over a ring.
- Functional analysis, which is the study of special kinds of infinite-dimensional vector spaces.
Quantum Mechanics
- Quantum information and computation, which, as stated before, is the use of quantum mechanical weirdness in building quantum computers, which could theoretically efficiently solve problems which we believe that classical computers cannot.
- Quantum field theory (QFT), which describes all particles as perturbations in fields. In QFT, particle number is not necessarily conserved, and special relativity is fully accounted for. Quantum field theory is possibly the best tested theory in all of physics, predicting the g-factor of the electron to thirteen decimal places and the Hall conductance to nine. When applied to electromagnetism, this is called quantum electrodynamics (QED). When applied to the strong force, it’s called quantum chromodynamics (QCD). When applied to the weak force, it’s called quantum flavordynamics (QFD), although people often resort to the electroweak model for this.
- Particle physics, the study of subatomic particles, which obey quantum mechanics. The current best accepted model of particle physics is the standard model, although we know that there are subtle some problems with it. There are also a lot of people trying to figure out how dark matter fits into all of this.
- String theory, loop quantum gravity, and other theories of quantum gravity. We’re really off the deep end here.
Acknowledgements
The linear algebra presented here is inspired by material from the following courses at UC Berkeley:
- Physics 89 (Austin Hedeman)
- Math 110 (Zvezdelina Stankova)
The quantum mechanics presented here is inspired by material from the following courses:
- Physics 5C (Mina Aganagic)
- Physics 137A (Austin Hedeman)
For further reading on linear algebra, especially in physics, some texts I can point to are
- Mathematical Methods in the Physical Sciences (Boas)
- Advanced Engineering Mathematics (Kreyszig)
- Linear Algebra (Friedberg)
- Linear Algebra Done Right (Axler)
- Linear Algebra Done Wrong (Treil)
Yes, I am not making those names up. This is actually what those books are called.
For further reading on quantum mechanics (and, believe me, if you want to actually know how to do quantum mechanics, you should read further), consider
